TechSEO Boost: “SEO Best Practices for JavaScript-Based Websites” Recap
January 10, 2018I don’t know about you, but here at Catalyst we’re still bursting with excitement over the amazing speakers and insightful content that came out of TechSEO Boost 2017. Hosted by Catalyst, TechSEO Boost was the industry’s first-ever conference 100% dedicated to technical SEO. It united leading minds in the industry to discuss the latest technical SEO trends, tactics, and innovations.
There was no shortage of amazing content to discuss, but in this post I’ll focus specifically on the JavaScript presentation from Max Prin, Head of Technical SEO, at Merkle.

SEO Best Practices for JavaScript-Based Websites
We all know that search engine crawlers can have a hard time crawling JavaScript-based websites. As a result, many SEOs try to steer brand managers, developers, and marketing teams from JavaScript-based platforms. But, let’s face it, some JavaScript-based websites are pretty slick and provide an excellent user experience. It’s time that SEOs strategically work around JavaScript and help clients and websites take advantage of the best that technology has to offer. Max Prin, Head of Technical SEO at Merkle joined the TechSEO Boost line-up to share some tactics and strategies that search marketers can use to help JavaScript-based websites receive more visibility from search engines.
Page Rendering on Google Search
Search engines are starting to crawl rendered pages instead of the source code. They know that a lot can be missed by just looking at the source code, but also know that crawling a rendered page can be time consuming and provide little value if the information is not displayed correctly.
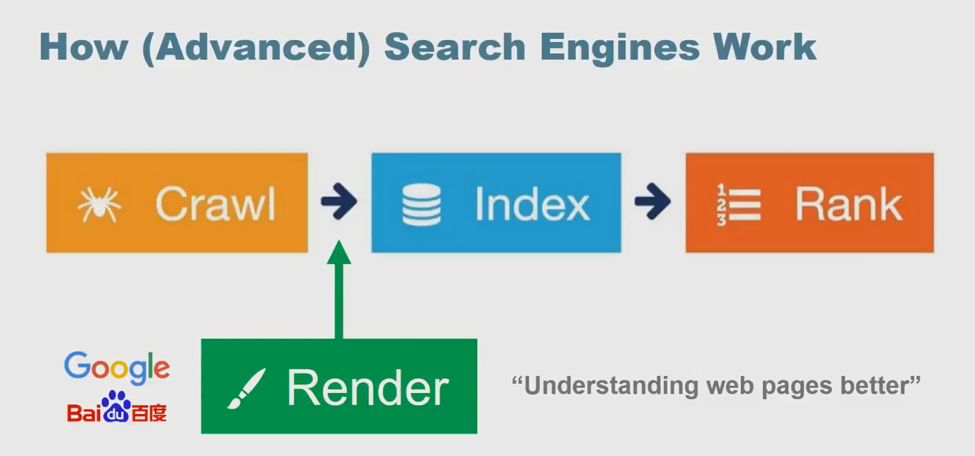
We’ll use Google as the example search engine for the rest of this post. Google will often crawl a website regularly through the source code, but in some instances it will crawl the rendered page before indexing. During his session, Max explained that Googlebot is using a web rendering service that is based on Chrome 41, and although this is an old version of Chrome, he says it’s a good place to start and recommended always optimizing to the latest version of Chrome.
URL Structure
URL structures are the first thing that crawlers see when accessing a page. Given this, it’s key that your URL is accessible by the search engines. However, JavaScript-based pages’ URLs can get pretty ugly and make it hard for the search engines to crawl.
Using Ajax, by default you get a URL similar to the one below:
Fragment Identifier: example.com/#url
This is not ideal because everything after the hash is not sent to the server. The search engines read it as example.com and not example.com/#url. The fix to this is the hashbang (#!), which was introduced by Google years ago. The hashbang was there to tell Google that they need to request a different URL and this URL is the escaped fragment URL. See below:
Hashbang: example.com/#!url
Google and Bing will request Example.com/?_escaped_fragment_=url

The idea behind this is that the escaped fragment URL should return an HTML snapshot of the page that the search crawlers can index but they would still show the hashbang URL. However, the hashbang ultimately causes a lot of back and forth and confusion. It’s anticipated that Google will eventually stop supporting the escaped fragment URL.
Given these shortcomings and changes, the current best practice is to use clean URLs and leverage the pushState function of the History API. This way all bots and crawlers will be able to follow the URL and they will look completely clean.
Internal Linking
This one might seem a little obvious but use classic <a href=”link.html”> when creating internal links. This is the best way that the search engines will be able to crawl and follow those links. Internal linking is very important throughout your website. It gives you the opportunity to promote content within your website. If the search engines cannot follow those links, you will lose equity.
Content Loading
There are many ways that developers and marketers can speed up load times for website content. One of these tactics is using a mega menu. It’s also great for users because it provides a lot of information in one place and can facilitate easy navigation.
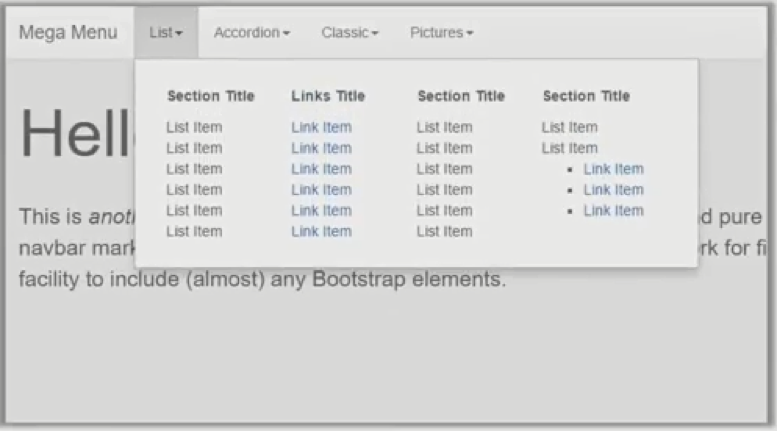
The problem with mega menus is that the search crawlers cannot access them on JavaScript-based sites. All of the effort put into creating this great link menu to boost internal linking is wasted, as the menu is not accessible by the search crawlers and the SEO value is lost. One workaround for mega menus is to use an HTML-based navigational structure.
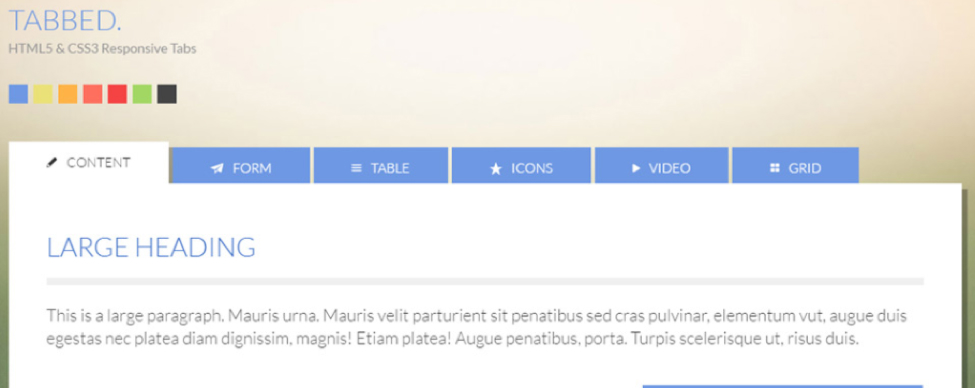
Tabbed content experiences similar issues. It might seem like a great idea to add tabbed content because it will speed up load times. The content on tab 2, 3, and 4 can load while the user is navigating the first tab. This seems like a great way to spread out content loading. HOWEVER, when Google lands on that page and the content is hidden within those tabs, it will be lost from search crawlers. Even if Google finds the content within those deeper tabs, it will be devalued because it is not the featured content on the page. It is best to create single pages for each one of those tabs.
Conclusion
At the end of the day, Max’s key recommendation for audience members was to make sure search engines can access and read your content. There is a lot of great technology that can be leveraged to make a website look great, but if the search engines cannot access that content, visibility is bound to drop. SEOs need to adapt and work around technology’s limitations to help maximize visibility and traffic regardless of technology. You can watch Max’s full presentation, along with the other TechSEO Boost presentations here. And, you can always drop us a line at info@catalystdigital.com to learn how to take your technical SEO to the next level.




